Google Trends Daten führen in die Irre
Gefährlicher als Unwissenheit ist trügerische Sicherheit: liegen uns Daten vor, denen wir vertrauen, treffen wir damit Entscheidungen, die wir so wohl nicht getroffen hätten, wenn wir uns nicht auf Daten hätten stützen können. Doch was ist, wenn uns diese Daten ein falsches Bild vermitteln? Und zwar so, dass wir es erst einmal gar nicht bemerken?
Genau das ist der Fall bei Google Trends. Das Tool, das seit 2006 darstellt, was die Menschen bei Google suchen, wann und wo, erfreut sich großer Beliebtheit: die Wirtschaftsweisen stützen sich auf diese Daten in ihrem Gutachten zu den Folgen der Corona-Krise, Wissenschaftler untersuchen damit unter Anderem die Verbreitung von Krankheiten, Journalisten und NGOs verwenden es als Teil der millionenschweren Google News Initiative für Recherche und Fact-Checking und Unternehmen beziehen Google Trends Daten in digitale Marketingstrategien ein, bei denen es alleine in Deutschland jährlich um mehr als 10 Milliarden Euro geht. Aktuell bewirbt Google Trends als Tool für Händler, um ihre Nachfrage auf Corona-Märkte einzustellen („Rising Retail Categories“).
Doch diese Daten sind so, wie sie für Jedermann abrufbar sind, nicht zuverlässig. Dies konnten wir in einer gemeinsamen Studie mit zwei renommierten Instituten der Universitäten Oldenburg und Hannover eindeutig belegen.
Die Google Trends Lotterie: Selbe Anfrage, andere Daten
Das Problem: Ruft man bei Google Trends Daten ab – zum Beispiel zur Suche nach „trockenem Husten“ im März 2020 –, erhält man Ergebnisse, die eindeutig und schlüssig aussehen. Ruft man jedoch dieselben Daten für denselben Zeitraum eine Stunde später erneut ab, erhält man andere Ergebnisse… die ebenfalls eindeutig und schlüssig aussehen, doch in vielen Fällen den zuvor angezeigten widersprechen.
Diese massiven – und zunächst unerklärlichen – Schwankungen sind uns aufgefallen bei unserer Arbeit an einem KI-gestützten Tool zur Trendanalyse, für das wir unter Anderem Google Trends Daten einbeziehen wollten. Zuerst hielten wir es für einen einmaligen Fehler in der Google-Datenbank. Dann konnten wir ihn über Tage hinweg verfolgen – und machten Google darauf aufmerksam. Als das Unternehmen verlauten ließ, die Abweichungen in den Daten seien lediglich klein und träten nur bei Nischenthemen mit geringer Suchnachfrage auf, stand dies in krassem Widerspruch zu dem, was wir beobachten konnten.
Gemeinsam mit der Abteilung Very Large Business Applications der Universität Oldenburg und dem L3S Research Center der Universität Hannover haben wir daraufhin das Problem über einen Monat lang anhand von mehr als 6.800 Suchabfragen verfolgt und vermessen.
Risiko für nicht verwendbare Daten: 25 Prozent
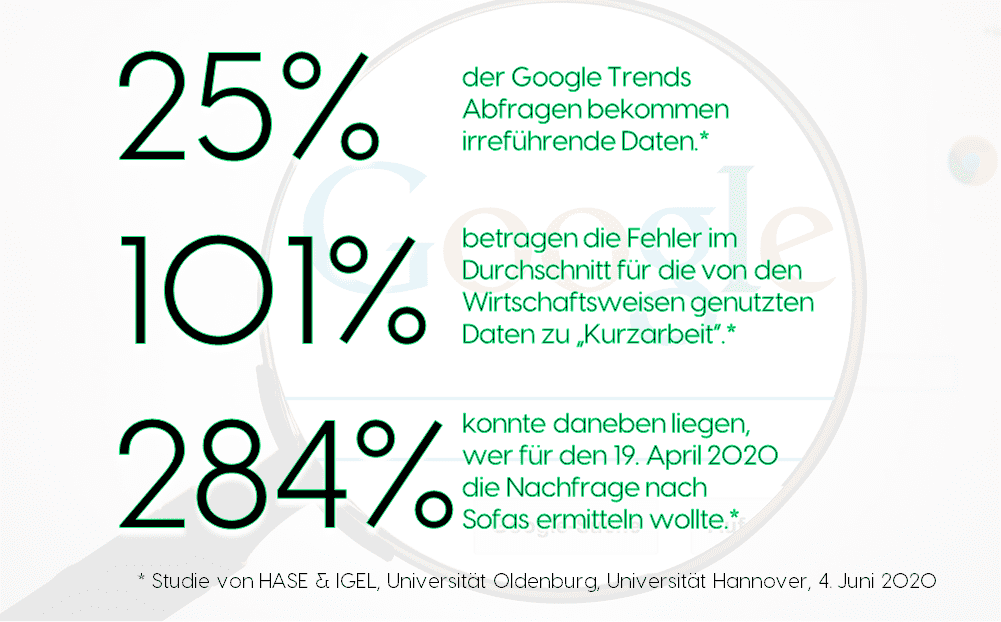
Das Ergebnis – am 4. Juni als gemeinsames Whitepaper veröffentlicht – spricht eine klare Sprache: in einem Viertel der Fälle unterscheiden sich Googles Antworten auf dieselbe Anfrage (z.B. „Kurzarbeit“ für 1. Quartal 2020), die zu zwei unterschiedlichen Zeitpunkten (z.B. einmal um 15:00, einmal um 17:00) gestellt wird, so stark, dass diese beiden „Stichproben“ nicht aus derselben Grundgesamtheit stammen können – dass also die Daten nicht vergleichbar sind. Für viele Begriffe liegen die Abweichungen noch viel höher:
Wer zum Beispiel Suchen zu „Change Management“ oder „Artificial Intelligence“ über ein Jahr hinweg (z.B. 2019) untersuchen möchte, erhält in mehr als der Hälfte der Fälle irreführende Daten. Sofern er aber nicht dieselbe Abfrage immer wieder tätigt, wird er dies nicht bemerken!
Größere Suchbegriffe und längere Zeiträume helfen – aber schaffen auch keine Sicherheit
Systematisch haben wir diese Widersprüche in den Daten beziffert und Muster darin gesucht. Die Erklärung von Google, dass nur Begriffe mit geringem Suchvolumen betroffen seien, konnten wir widerlegen. Zwar führen mehr Suchen zu besserer Datenqualität, doch erklärt dies bestenfalls die Hälfte der Schwankungen in den Daten – und ist vor Allem keine Versicherung: auch für Begriffe mit hunderttausenden Suchen widersprechen sich die Angaben zum Teil um bis zu 248 Prozent. Auch hat der durchschnittliche Nutzer von Google Trends – im Gegensatz zu Data Scientists, die verschiedene Datenquellen integrieren – gar keine Möglichkeit, das Suchvolumen zu berücksichtigen: Google gibt dieses nur für größere Werbetreibende in Google Ads an, in Google Trends wird lediglich ein Index bereitgestellt, der – wie wir zeigen konnten – nur zur Hälfte mit dem tatsächlichen Suchaufkommen eines Begriffs zusammen hängt.
Es gilt also: Begriffe mit mehr Suchaufkommen zu untersuchen, schafft etwas mehr Sicherheit – aber bei Weitem keine Garantie für verlässliche Ergebnisse. Und: der Nutzer muss dafür das Suchvolumen überhaupt erst einmal kennen!
Was wir stattdessen herausgefunden haben: vorbeugen gegen unzuverlässige Google Trends Daten kann man am Besten, in dem man sie für lange Zeiträume abruft. Weichen Googles Daten bei Abfragen für Zeiträume unter 8 Monaten um durchschnittlich 35% voneinander ab (mehr als ein Viertel der Abrufe sind gar nicht miteinander vergleichbar), ist das Problem wesentlich geringer ausgeprägt, wenn man Zeiträume von mindestens 5 Jahren abruft. Wirkliche Sicherheit verschafft hingegen auch das nicht: auch für solche langen Zeiträume sind immer noch Abweichungen von über 100 Prozent möglich – und auch bei großen Themen wie „Notre Dame“ ist beinahe jeder sechste Abruf nicht sinnvoll verwendbar.
Kurzum: wer mit Google Trends Analysen auf Ebene einzelner Stunden oder Tage machen möchte – wie zum Beispiel die Kriminalpolizei im Mordfall Lübke – bewegt sich gefährlich nah am okkulten Reich der Wahrsagerei. Wer lange Zeiträume betrachtet und damit lediglich wochen- oder monatsweise Aussagen treffen kann, hat eine höhere Trefferquote – kann sich aber immer noch nicht sicher sein, ob seine Daten stimmen.
Arbeit mit Google Trends Daten: ein Fall (nur) für Profis
Beide Stellhebel – das Suchvolumen ebenso wie die Länge der untersuchten Zeiträume – erklären einen Teil der Widersprüche in den Google Trends Daten, doch zeigen auch sie nicht das ganze Bild: immer wieder haben wir Schwankungen entdeckt, die viele – untereinander völlig unverbundene – Begriffe betreffen. So scheint die Datenqualität in abends und nachts besser zu sein als mittags, teilweise zeigt Google auch für mehrere Tage durchweg verlässliche Daten an, um dann wieder einen bunten Flickenteppich zu liefern. Hier sind offenbar Google-interne Prozesse am Werk.
Für Data Science Experten ist der Umgang mit solchen „Wildwasser-Passagen“ in Daten kein Problem – wenn erst einmal erkannt wurde, wo und wie sie auftreten, können wir damit umgehen. Wir ermitteln automatisch, welche Daten nicht zu retten sind und rechnen aus denen, die verwendbar sind, die Schwankungen heraus.
Das gilt jedoch nicht für den üblichen Google Trends Nutzer: er hat weder eine Möglichkeit das Problem zu erkennen, noch es zu bewerten, und schon gar nicht, es zu bewältigen. Drei Expertenteams – von HASE & IGEL, L3S und VLBA – haben Wochen und tausende Messungen benötigt, um einen Umgang zu finden.
Wie ist es mit dem Mittelständler, der nach guten Begriffen für seine Werbung sucht? Dem Journalisten, der schnell einen Trend für einen Artikel überprüfen will? Selbst zahlreiche wissenschaftliche Studien, die mit Google Trends gearbeitet haben, sind nicht wiederholbar.
Google muss seiner Verantwortung nachkommen
Google bewirbt Google Trends als handliches Tool für Jedermann. Hier appellieren wir klar und laut an den Marktführer, seiner Verantwortung gerecht zu werden:
Google muss entweder eine ausreichende Verlässlichkeit der Daten sicherstellen, oder zumindest mit einer „Ampelkennzeichnung“ für Jeden verständlich anzeigen, wie verlässlich die gerade ausgelieferten Daten sind. Möglich wäre das problemlos – wir haben es ja schließlich auch geschafft! Google – it’s your turn…